分享互联网新闻
更新时间:2017-10-23 06:03点击:

谁能想到,我们会在一年之内连续被AlphaGo刷屏两次?关于阿尔法元如何快速学习成长击败AlphaGo Lee和AlphaGo Master的新闻这里就不再赘述,给出两个关键信息,供读者一起思考。
一、阿尔法元没有录入人类棋谱数据,单纯通过自我对弈,依靠强化学习取得了现在的能力。
二、阿尔法元的工作和训练效率都有了很大的提升,仅用了三天的时间就能击败原版阿尔法狗,同时在推理时,阿尔法元只用了4块TPU。
阿尔法元之所以震撼了整个业界,是因为当我们以为Master已经封神时,它用三天的时间告诉人类,人类以为的最高水平,在机器面前不值一提。人类经验成了阿尔法狗的累赘,甩掉这些,算法可以更快更好的完成任务。
对于很多人来说,这是一个巨大的打击:我们引以为傲的大数据不仅仅会误导算法,还会占用更多的计算资源,阻碍了通用人工智能的发展。
这篇文章的主要任务,就是来安抚一下惊慌失措的人类。先从第一个问题说起,看看阿尔法元到底是怎么提升计算效率的。
从监督学习到强化学习以前在国际象棋的人机对弈中,计算机使用暴力穷举法推算双方对峙时的种种可能,通过运算速度取胜。可穷举法一度曾经被认为不适合围棋,围棋每走一步就会创造出19×19种可能,运算量太过巨大。
直到有人开始用卷积神经网络解决围棋问题,用卷积神经网络擅长的降维降低搜索空间,机器便有了战胜人类的可能。
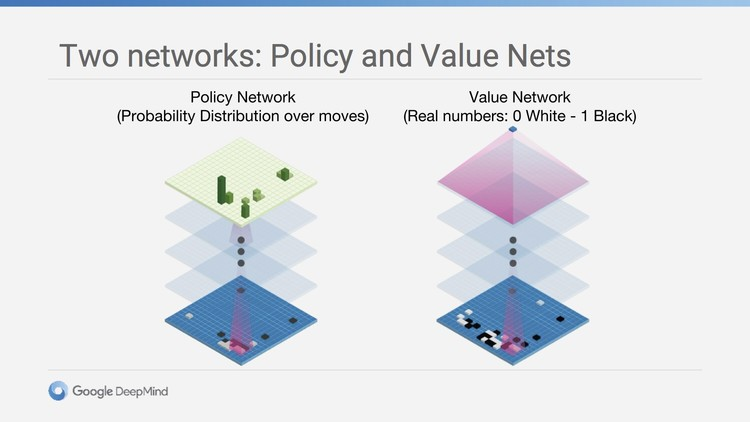
在击败了柯洁的阿尔法狗大师版本中,应用了整整40层的策略网络/价值网络,前者用于确定当前局面,预测下一步行动,价值网络则用来判断执黑执白两方的胜率。另外,还要加入快速走子系统,以在稍微牺牲走棋质量的前提下,极高的提升运算速度。最后,再用蒙特卡罗树搜索算法把以上三者连接起来。
而阿尔法元则直接将策略网络和价值网络相结合,并且去掉了快速走子系统。也就是说,以往由三部分组成的阿尔法狗在如今直接变成了一个整体。
简化之后,策略+价值网络的输入特征由48个减少到了17个,加上被删掉的快速走子系统,基本关于人类围棋的知识都被去掉了。

从图中可以看到,没有任何人类知识的阿尔法元,在自我对弈的初期常常出现一些毫无逻辑的诡异棋局,可到了后期,却总能有出其不意的打法。
去掉人类已知知识的特征输入,意味着阿尔法元从监督学习走向了强化学习——分裂成两个一无所知的棋手,开始对弈,出现胜者后用结果进行训练,然后继续循环对弈。
而走向强化学习,不仅仅是因为去掉了人类棋谱的监督,还有关于残差网络的应用。残差网络可以理解为卷积神经网络的深化,简单来说,就是尽量减少每一层网络的神经元,而把网络做的更深。结合阿尔法元从监督学习转向强化学习,减少了输入特征,也利于把整个神经网络做的更加简单粗暴。
总之,阿尔法元的重点就在于,去掉人类的围棋知识所需的计算的资源,把网络做的更深,好让阿尔法元在越来越深的网络中自己发现这些知识。
而阿尔法元的确做到了。
甩掉数据,通用人工智能就来了吗?所以,阿尔法元效率提升的重点在于,去掉人类数据的监督,才有可能实现结构的优化。
那么同样的套路,可以应用在其他领域吗?
答案很有可能让人失望。
首先,围棋这种游戏本身就是透明规则的数学计算,此前的Master和Lee,无非是在没法单纯使用推理时的权宜之计。到了其他无法使用通行透明规则的领域,深度学习可能就没那么好用了。

今年DeepMind对《星际争霸》的挑战就是案例之一,把整个游戏拆分成多个仿真场景,企图以分布式的模拟训练解决整体问题。可目前来看,结果却不尽如人意。毕竟在不完全信息环境中,对长期规划能力、多智能体协作能力的考验都太过严苛了。机器都不一定能很好的模仿人类的经验,更不必提完全依靠机器的自己了。
在强化学习中,最容易出现的情况就是机器只顾获取单一条件下的奖励,无法顾及到多任务环境中的整体进程。
游戏中尚且如此,那在语音识别、图像识别等等其他领域中,数据的价值就更为重要了。现在提出强化学习=通用人工智能,还为时尚早。
所以,没有必要因为数学游戏中的失败就去否定人类存在的价值。用自己短处去和机器的长处相比,才是最没意义的事。
人类限制了机器的想象力吗?而提到人类的短处,就不得不说在阿尔法元和Master对弈中发现的有趣的信息。对典型的,就是在人类的影响下,Master常常走向局部最优。而一些围棋手们在刚刚接触围棋时就要学习的打法,阿尔法元却在训练的极后期才能发现。
用我们常常评论学校教育的话讲,就是人类的规则限制了机器的想象力。
这一切提醒了我们两件事,第一,由于人类自身能力所限,我们常常限于局部收敛而不自知,进而会影响机器学习的能力;第二,大数据中的信息噪声不可忽视。
也就是说,如果总是依靠人类经验和数据,依靠机器学习的人工智能的水平顶多是一个脑子特别好使人类。
而阿尔法元的成功,是不是告诉了我们,依靠强化学习绕过大数据的局限、甚至是人类本身的局限?
虽然在很多没有明确规则的场景中强化学习还表现乏力,但我们是否可以创造仿真环境,尝试用强化学习重新解读那些我们习以为常的基础问题?比如分子的组成和运动甚至基础物理,以此能影响到的材料、生物等等领域,都有着无限的想象空间。
阿尔法元对通用人工智能的推进虽然有限,却证实了用物美价廉的强化学习解决更多问题的可能。在未来,我们可以期待更多商业化的场景,看看强化学习是不是真的能让机器学习有更多的应用空间。
作为一个从小就数学不好的人,我非常坦然的接受了自己的失败——作为人类,我们的计算能力的确输了机器一大截。那些通过计算而得来的智慧,显然也不见得比机器更高明。
可我们存在的意义,从来不是算数,而是把自己的能力付诸到更高级的系统上,发挥出更强大的作用。就像我们不曾被计算器打败一样,虽然在计算这件事上,阿尔法元青出于蓝。可换个角度想想,我们自己作为算法的发明者,看着自己的造物补足了自己能力上的不足,是不是应该露出造物神一样的微笑呢?